The New Agent Operations Playbook: What OpenAI’s Latest Signal Means for Founders, RevOps, and CX Leaders
OpenAI’s latest agent-focused update signals a shift from AI pilots to agent operations. Here’s how business teams can deploy, govern, and scale now.
# The New Agent Operations Playbook: What OpenAI’s Latest Signal Means for Founders, RevOps, and CX Leaders **Meta description (153 chars):** OpenAI’s latest agent-focused update signals a shift from AI pilots to agent
The New Agent Operations Playbook: What OpenAI’s Latest Signal Means for Founders, RevOps, and CX Leaders
Meta description (153 chars): OpenAI’s latest agent-focused update signals a shift from AI pilots to agent operations. Here’s how business teams can deploy, govern, and scale now.
OpenAI’s newest enterprise-facing message is clear: we’re moving from “AI as a feature” to agents as an operating layer for everyday business work. While the market has spent the last year testing copilots and one-off automations, the emerging pattern is bigger: high-performing teams are stitching agents into revenue workflows, service operations, and internal execution loops.
For business leaders, this is not just a model upgrade story. It’s an operating model shift.
If you’re a founder, operations leader, RevOps owner, or CX executive, the practical question is no longer *“Should we try AI?”* It’s *“How do we run agentic work reliably, with measurable outcomes and controlled risk?”*
Why this update matters right now
The strongest signal in this cycle is that major labs are framing agents around real work orchestration, not chat novelty:
Multi-step task handling
Tool usage (systems, data sources, business apps)
Human handoff when confidence drops
Persistent context and workflow memory
Better alignment between intent, execution, and outcome
For business teams, those capabilities map directly to high-value operational bottlenecks:
Lead qualification and routing delays in RevOps
Repetitive support triage in CX
Cross-system swivel-chair work in operations
Slow internal decision cycles due to fragmented data
In other words, the commercial impact comes from reducing cycle time and increasing throughput in core processes—not from adding another chatbot to the website.
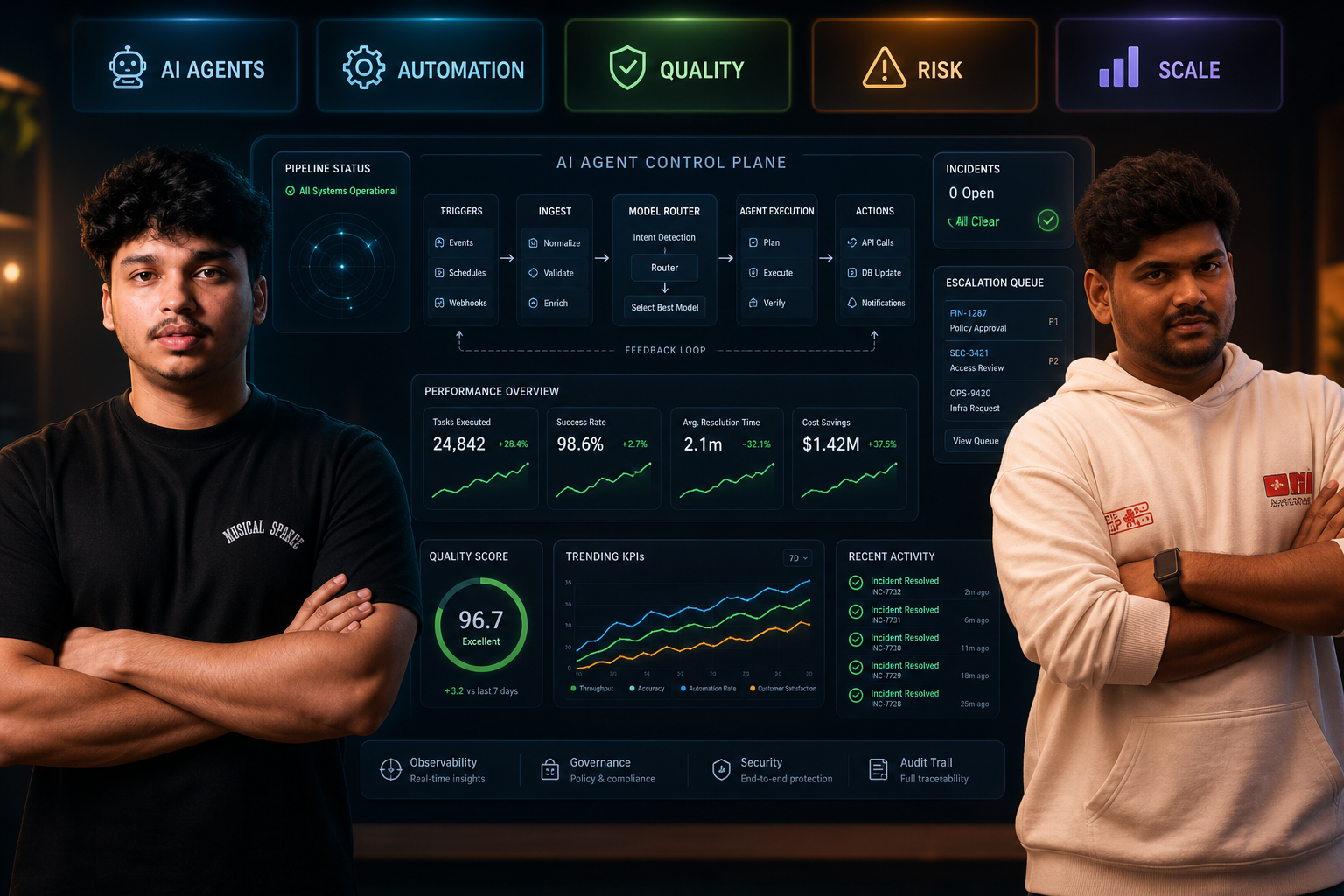
The biggest shift: from “single model” thinking to “agent operations”
Many companies are still running AI with a legacy mental model: prompt in, answer out, done. But production deployments are trending toward a more robust stack:
1. Task router: Sends work to the right model/tool path based on complexity, cost target, and SLA.
2. Workflow engine: Breaks requests into steps, validates outputs, retries when needed.
3. Governance layer: Enforces policy, access rules, logging, and escalation.
4. Measurement loop: Tracks latency, unit economics, and quality by workflow stage.
This is where AI initiatives either graduate into business infrastructure—or stall in pilot mode.
What founders and operators should do in the next 30 days
Here is a practical sprint plan that works across startups and mid-market teams:
1) Pick one revenue-adjacent workflow
Start with a workflow where delay or inconsistency already hurts revenue or retention. Good candidates:
Inbound lead enrichment + qualification
Renewal-risk account monitoring
Tier-1 support triage and response drafting
Post-sales onboarding task coordination
Avoid broad “company-wide AI” mandates at this stage. One narrow, high-frequency workflow is better.
2) Define success as operations metrics, not model metrics
Most teams over-index on benchmark scores and under-index on business throughput. Track:
Time-to-resolution
First-response time
Escalation rate
Cost per completed task
Human override frequency
This makes buy-in easier across finance, operations, and leadership.
3) Design the human handoff before launch
Production agent systems need explicit handoff paths. Decide up front:
When confidence is too low
Which roles receive escalations
What context package is transferred
What response-time SLA applies
If handoff logic is vague, trust erodes quickly.
4) Build for observability from day one
At minimum, log:
Task inputs/outputs by stage
Tool calls and failures
Retries and fallback triggers
Latency and spend per run
Without observability, you can’t improve quality or control cost.
5) Create a weekly “agent ops review” cadence
Treat AI workflows like any critical business system. Weekly review should cover:
Quality drift
Cost anomalies
Prompt/workflow changes
New failure patterns
Next week’s optimization experiments
This operating cadence is what separates successful deployments from static demos.
Common execution mistakes we keep seeing
As adoption accelerates, the same pitfalls keep appearing:
Mistake 1: Tool sprawl too early. Teams connect too many systems before validating one workflow.
Mistake 2: No routing strategy. Every task goes to the same expensive model regardless of complexity.
Mistake 3: No policy boundary. Access controls and compliance checks are bolted on late.
Mistake 4: Success defined as “it works.” No baseline metrics means no measurable ROI.
Mistake 5: No owner. Agent operations need clear ownership across product, ops, and security.
If you avoid these five, your chance of reaching stable production rises dramatically.
What this means for 2H planning
For US/UK/EU business teams planning the next two quarters, the strategic takeaway is simple:
AI strategy is becoming workflow strategy.
Competitive edge will come from execution quality, not just model access.
The winners will be teams that operate agents with discipline: routing, governance, observability, and continuous optimization.
This is especially true for RevOps and CX functions, where small latency and quality gains compound fast across thousands of interactions.
Final takeaway
The latest market signal around agents should push leaders past experimentation. The opportunity now is to build a repeatable agent operations layer that improves speed, quality, and cost control across real business workflows.
If your team is still in pilot mode, this is the moment to move from isolated demos to operational design.
---
Need help building an enterprise-ready agent workflow?
GOFTUS helps founders and operations teams design, deploy, and scale custom AI systems with governance, routing, and measurable business outcomes built in. Book a GOFTUS consultation to map your first production-grade agent workflow.